
Large Language Models – Do you really know the difference between ALPaCA and LLaMa?

They may look similar but licensing restrictions on Large Language Models (LLMs) can have some very distinguishing features. You’ll want to learn to stay safe/keep from tripping up in the new world of LLMs.
There is so much excitement/buzz surrounding large language models (LLMs) – the powerful tools reshaping how we work, how we write emails, post blogs, generate text, translate languages, etc. These amazing tools don’t come without restrictions and limitations that companies should thoroughly vet before using an LLM algorithm to train their own, proprietary large language model.
You guessed it – the licensing restrictions vary depending on the LLM that is being used. For code, data and weights we most often distinguish between open source and proprietary:
- Open Source:
- Code – available for anyone to use, often created by [ ].
- Data – publicly available, such as the text of Wikipedia.
- Proprietary:
- Code – owned privately and not available to the public.
- Data – examples, text of emails or customer reviews.
Companies should carefully consider the licensing restrictions for each of the elements of an LLM before using it. By understanding the licensing restrictions, companies can ensure that they are using the LLM in a compliant manner.
Here are some additional things to consider when evaluating the licensing restrictions for an LLM:
- The purpose of using the LLM. If the LLM is being used for commercial purposes, the licensing restrictions may be more stringent compared to educational or non-commercial purposes.
- The intended audience for the output of the LLM. If the output of the LLM will be made public, the licensing restrictions may be more restrictive.
- The potential impact of the LLM on others. If the LLM could be used to create harmful content, the licensing restrictions may be designed to prevent this from happening.
Four of the most popular LLM algorithms are LLaMa, ALPaCA, MPT-7B and OpenAI; here is a table showing their licensing restrictions:
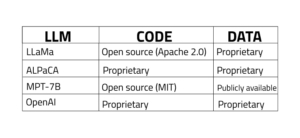
- LLaMa is an open-source LLM that is licensed under the Apache 2.0 license and is available for anyone to use, modify, and redistribute. However, the data that LLaMa is trained on is proprietary and cannot be shared with others.
- ALPaCA is a proprietary LLM that is owned by Google AI. The code for ALPaCA is not available to the public, and the data that it is trained on is also proprietary.
- MPT-7B is an open-source LLM that is licensed under the MIT license. This means that the code is available for anyone to use, modify, and redistribute. The data that MPT-7B is trained on is also publicly available.
- OpenAI is a proprietary LLM that is owned by OpenAI. The code for OpenAI is not available to the public, and the data that it is trained on is also proprietary.
It is important to note that these licensing restrictions may change over time. Companies should always check the latest licensing information before using an LLM.
For more information on the legal resource, visit: NLP Logix – AI Realized – NLP Logix or Home – ADVOS | Strategy + Law (advoslegal.com)
Leave a Reply